Many thanks to Bob DuCharme, Oren Ben-Kiki, Joe Kesselman, Jeffrey Sussna, Paul Rabin, James Anderson, Nathan Kurz, Rick Jelliffe, and David Jackson for their comments. All mistakes are mine, of course.
The XML 1.0 recommendation and many of its sibling standards (XLink, XSL, and possibly schemas) are simplifications of more complex systems, but still perform multiple complex tasks in single standards. While XML 1.0 itself is a dramatic step forward for structured formats, simplifying document markup and amplifying its power simultaneously, the recommendation still has some complications. The recommendation keeps well-formedness and validity deeply intertwined, and provides options for parsers that complicate the situation further. The relationships between XML 1.0 and namespaces are already complex, and the relationships between XML itself, XLink, XSL, schemas, and other XML projects are unclear at best. It's not clear from reading individual standards how they are supposed to interact with each other, and dependencies between them may introduce additional processing overhead that isn't always needed.
Instead of creating a denser thicket of standards, it would be extremely helpful if the standards-builders would create standards as independent modules that can be layered, and a separate standard allowing documents to identify appropriate layering possibilities. This would simplify the task of programmers, allowing them to create modules independently, without concern for unwanted interactions, and similarly ease the task of authors and other document developers, providing them with a consistent (or at least specifiable) environment their documents can inhabit. Making this work smoothly may require fragmenting the XML 1.0 specification itself into a larger group of standards, providing more control over individual atoms and creating a more flexible and more reliable environment for document processing. Once that fragmenting is complete, the place of sibling standards can be more precisely located and a processing framework for XML established on a sounder foundation.
The first step toward a layered approach must be the fragmentation of XML processing. While layering, in the sense of an application relying on a parser for services, can still have benefits if XML 1.0 document processing is treated as monolithic, it makes it very difficult to replace DTDs with schemas, perform validation on transformed documents, or more precisely control the behavior of XML parsers with regard to issues like use of external resources. Building all of these functions into a single standard and reflecting that standard with monolithic software makes it difficult to pass XML-derived information to a new round of processing without going through the processing-wasting process of reserializing the document into XML and parsing it back out of XML. While this may be appropriate for some distributed applications, the design of parsers that produce events or trees as output but only accept documents as input is a stumbling block for efficient architectures.
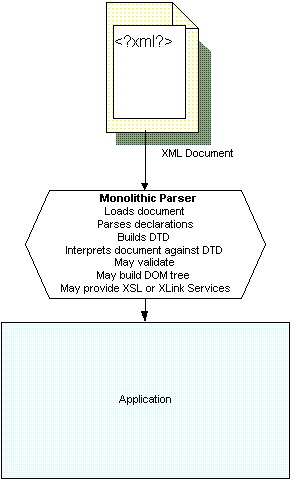
The XML standard presents two different types of processors (more commonly called parsers), validating and non-validating, as well as some options for non-validating parsers. The XML 1.0 standard describes both in the same document, making it fairly difficult to determine the differences, apart from the validating parser's additional testing of document structures. Both types of parsers have to perform some processing of declarations if they are present, but the results of that processing are far less reliable in non-validating parsers. Nonetheless, the creation of parser components has at least taken a significant first step toward the creation of modular XML processors, as shown in Figure 1.
Figure 1- Applications can use monolithic parser components to reduce the amount of processing they must provide for XML documents.
Typically, building a parser is beyond the skills or interest of developers building XML applications. Instead of re-inventing the wheel, developers locate a parser whose feature set meets the application's requirements, and wire the parser to the application. The application then receives a parsed form of the document, which can be readily used with (or as) its internal structures. The application needs to know how to handle the information returned by the parser, but doesn't need to know any of the details of the parser's internal operations. Parsers vary widely in much more than the simple well-formed vs. valid distinction proposed by the specification. Some parsers, like Aelfred, are optimized for quick lightweight processing, and don't enforce the complete set of well-formedness constraints on documents. Other parsers, like Expat, perform much more complete processing, but don't retrieve external resources (like Aelfred does.) Larger parsers, like IBM's XML4J and Sun's Java Project X, combine a variety of different possibilities into a single set of parser mechanisms. Error handling is another field with enormous variability, especially among validating parsers. Choosing a parser that matches an application's requirements closely can take a good deal of research and experimentation.
Two standards dominate the field for transmitting information between the parser and application: the Simple API for XML (SAX) and the World Wide Web Consortium (W3C)'s Document Object Model (DOM). SAX, created by the members of the XML-Dev mailing list, is an event-based tool, more or less 'reading' the document to the application using a set of named methods to indicate document parts, while the DOM specifies a tree which applications may then explore or modify. SAX is typically used where efficiency and low overhead are paramount, while the DOM is used in cases where applications need random access to a stable tree of elements. (Many parsers support both.)
Note:SAX and the DOM are most comparable in a Java environment. A Python implementation of SAX is available, and the DOM is specified in JavaScript and IDL as well as Java, but Java seems (at present) to be the main arena for XML processing standards.
The next three examples will explore scenarios ranging from the simplest and most lightweight parsing - non-validating parsing returning SAX events - to the heavyweight battleship of validating parsers that return a DOM tree to the application. (Non-validating DOM parsers do exist, as will be noted in the last scenario.)
Please note that none of the following scenarios is based on the architecture of any particular parser; rather, they are based on the requirements established by the XML 1.0 recommendation and to some extent by the supporting SAX and DOM specifications.
The lightest approach to XML parsing is the use of a non-validating parser that returns SAX events to the application. This way, no tree structure needs to be built and no validation needs to take place, reducing the overhead involved and making it easy to create applets and other highly optimized applications. Despite its lightweight appearance (in comparison to validation and DOM-based approaches), a non-validating parser still has an enormous amount of work to do in processing documents. Although non-validating parsers can work with documents that utterly lack a DTD, they are expected to process certain categories of declarations, including entity and attribute declarations. Non-validating parsers have considerable work to do that extends well beyond their foundation in checking document syntax.
The task of non-validating parsers has been lightened to some extent by the XML 1.0 recommendation's making the retrieval and use of external DTD resources optional. While this has made it easier to write non-validating parsers, it has also made it difficult for document authors to use some of the tools (entities and default attribute lists) that non-validating parsers are supposed to support. Non-validating parsers effectively do too much, but don't do it reliably.
The steps a non-validating SAX parser must go through to parse a document and present it to an application are shown in Figure 2. Arrows represent the flow of document (including DTD) information.
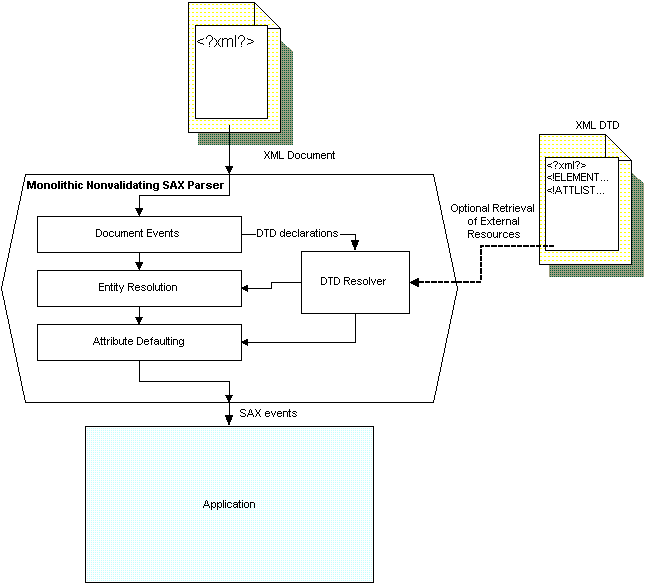
Figure 2 - Non-validating SAX parsers still have a considerable amount of processing to do.
DTDs perform a number of separate tasks, carrying text substitution information, attribute default information, and document structure information. Non-validating parsers must process all but the last of those types of information, though they may also ignore such information when contained in files external to the document. For the most part, applications get thoroughly processed documents, though traces of entities may remain in the event stream.
Validating SAX parsers perform all of the tasks that non-validating SAX parsers perform, plus the enforcement of additional constraints, most of which relate to checking DTD and document structures. The DTD resolver needs to support and process more declarations, but otherwise a layer for document structure testing rests on top of the previous path, validating that structure before passing it to the application (and reporting errors if there are any.) Figure 3 shows the path of document and DTD information through a validating SAX parser.
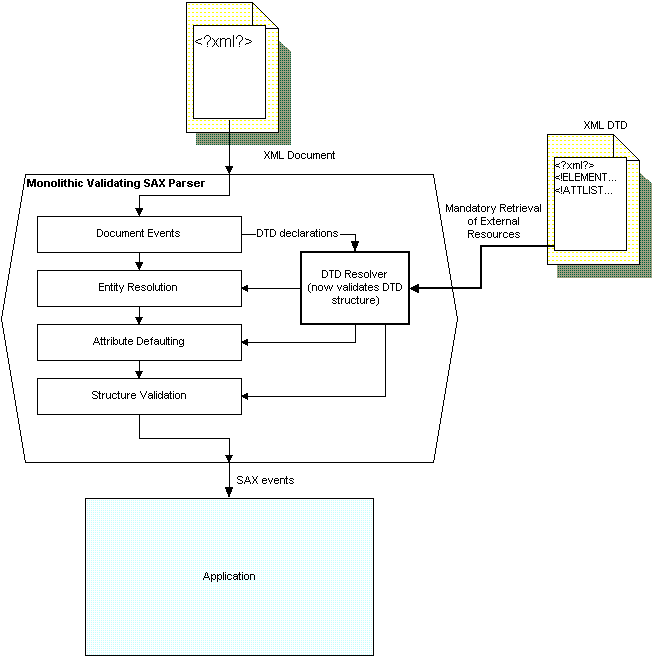
Figure 3 - Validating SAX parsers add an extra layer of processing, retrieve external resources, and check DTDs more closely.
A validating DOM parser builds on the SAX parser shown above by creating a tree structure as its output. DOM tree objects may then be handled outside of the parser and inside the application using either the W3C's standard interfaces or vendor-specific additions to that interface. Figure 4 shows this additional step and the required additional support inside the parser.
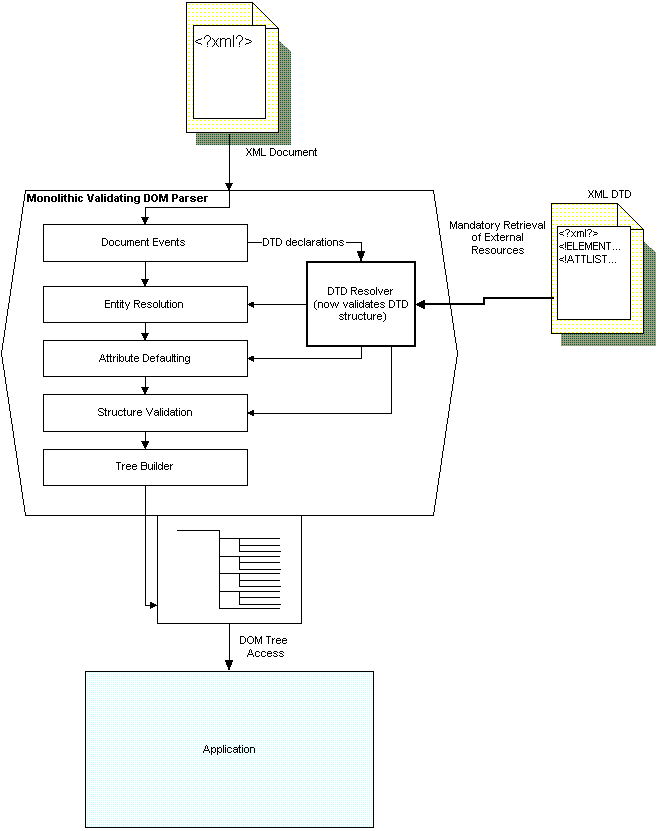
Figure 4 - Validating DOM parsers add an extra layer of tree builder and return a single object rather than (or possibly in addition to) a series of events.
While it is possible (using the Docuverse DOM or possibly the IBM XML4J parser) to build a DOM tree from SAX events returned by any SAX parser, most of the larger parsers provide their own proprietary tools for building DOM trees as an integral part of their product.
Note:For an excellent brief summary of what XML processors (aka parsers) must tell the application and what they should and may do, see John Cowan's Non-Validating Parsers: Requirements, Full Disclosure and Full Disclosure II emails at the XML-Dev archives.
Opening up these parsing processes would allow several major advances. First, applications could have more control over the parsing process, choosing components that would, for instance, always load (or not load, or be configurable) external resources, resolve entities, or pass a copy of the DTD to the application. Second, the components could be run in different sequence in conjunction with other XML standards. DTDs could be applied to transformed versions of documents to make sure they are appropriate input for a process, rather than to the original version. DTDs could be swapped out for other schema validation modules, opening up the process. Namespace processors and DTD transformations could be inserted into the parsing process, removing a source of potential conflict. Finally, structural validation could be easily applied to XML 'documents' stored in media other than traditional text files, like object-oriented data management systems. Rather than parsing a serial file, an XML processor could operate directly on information sent to that processor as events.
A componentized parser would come in several pieces. At the foundation would be a bare-bones parser that did nothing but read files and check document syntax. It would route DTD events along one path, and document events along another. Applications could accept that information directly (which might be appropriate for authoring tools), or direct it to other components that did things like expand entities, provide attribute defaults, provide schema validation, or build document trees.
Instead of the monolithic parser, applications would have a set of components which they could link and configure to create a 'parser' more to their liking, looking like the pieces shown in Figure 5.
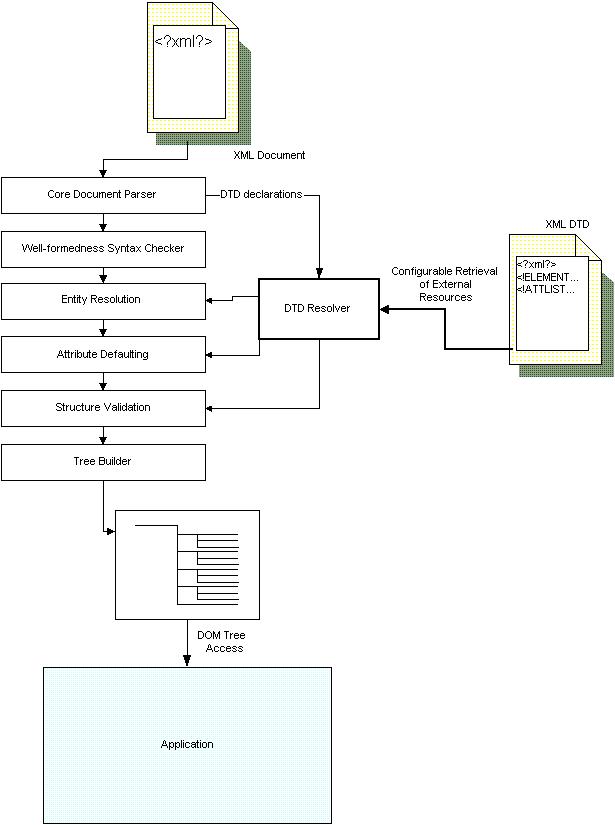
Figure 5 - Building a validating, tree-building parser out of standard components.
Once this process is complete, adding other standards to the mix becomes much easier. Figure 6 demonstrates how adding some components can add namespace-awareness to the parsing process shown in Figure 5.
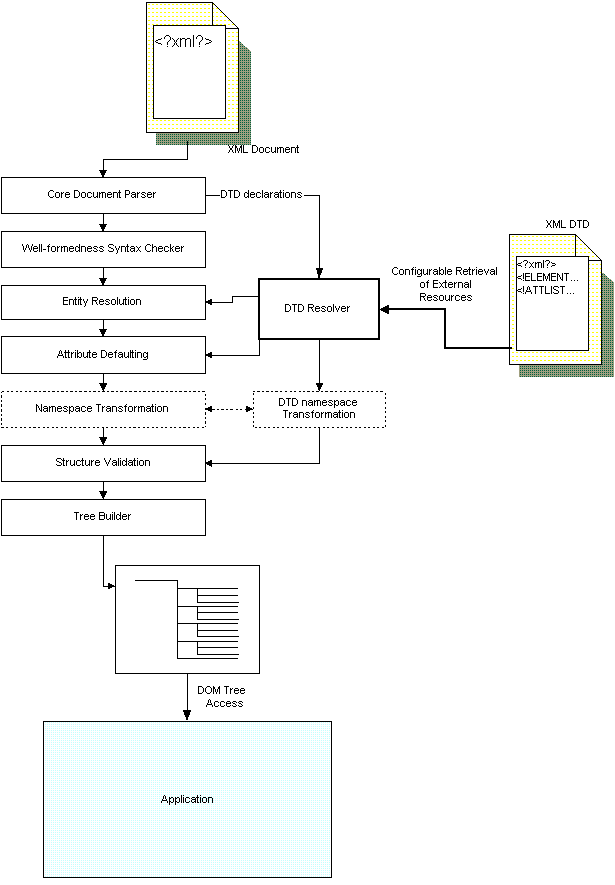
Figure 6 - Building a namespace-aware, validating, tree-building parser out of standard components.
Adding components to the middle of the process is only one advantage of this architecture. So far, all of these examples have started with an XML document as the input source. By creating different entryways for information that translate their sources to the necessary events, developers can connect XML documents, HTML documents, relational databases, and object databases directly to processing without having to go through the extra overhead of creating a serial XML 'document'. They don't need to lose the services provided by XML processing (entity expansion, attribute defaulting, etc.), so long as their entryway adds the needed events to enable this processing. Figure 7 shows what this might look like.
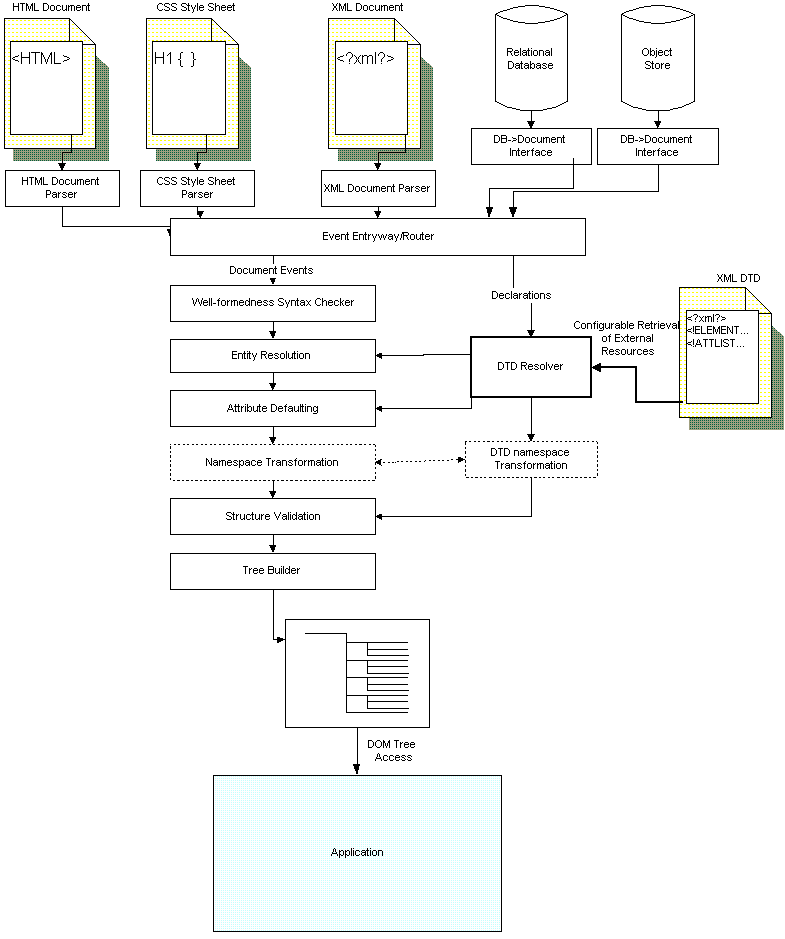
Figure 7 - Building a namespace-aware, validating, tree-building parser capable of working with multiple input sources.
An approach like this might also simplify the task of processing XML information in forms more complex than single documents, like streams of multiple XML documents. By using the simplest possible lexical parser at the bottom level, and modules above it for routing streamed information to their proper processor, support for streams could be added to this architecture without requiring a complete rebuilding.
'Rationalizing' the processing of an XML is a big step forward for XML application development, moving into a second generation of parser technology that is far more configurable and potentially more capable than the first generation of monolithc parsers. Unfortunately, the XML standard, which still provides the foundations, is not very accomodating to such an approach, using its own set of intermingled options (well-formed/valid, loading external resources or not, handling namespaces, a new layer, or not). Simplifying XML processor development to take advantage of a cleanly modular approach might well require breaking the XML standard into at least three pieces, possibly four:
Note that this doesn't require multiple standards documents - these pieces could all occupy different sections of the same document. It would require, however, clean separations between layers and a reorganization of discussions about processing. This may not be something that happens immediately - XML needs some stability to convince adopters that it's ready for real applications - but is definitely worth considering when the next round of XML development arrives.
Once XML itself has been modularized, it becomes much easier to describe other standards in terms of their location in this process, and to create components that provide support for those standards. Some standards (like schemas) already have a fairly clear place in the open parser model above, potentially fitting in alongside the DTD resolver and replacing the structure validation component. Other standards, like architectural forms, could plug into the open parser either before or after validation, depending on whether the original document or its transformation is the 'real' target of validation. (Given an appropriate framework, it is conceivable that documents of different types could be routed through different processing chains, allowing an application to load both documents built to a particular standard and documents that need to be transformed to meet the same standard through a single gateway.)
Other standards are more complex. XSL contains at least two parts, one for transformations, the other for styling. XLink's relation to this chain is also unclear and depends on a number of issues relating to link resolution's possible entanglement with styling in some form. Some standards (like Cascading Style Sheets) operate only after the tree construction has been completed, and effectively work above this level of processing.
Two other standards may have an effect on this processing. The possibility of document fragments, especially fragments that aren't well-formed, may require a different set of tools at the very beginning of the parsing process. The simultaneous work on 'canonical' XML documents, which don't require entity expansion or attribute default provision could simplify the processing, removing several layers from the parsing process. A modular description of that process could make the creation of lightweight processors for canonical documents a matter of configuration, rather than requiring the modification of parsers to strip out unneeded code.
Making this modular approach work well across multiple document types and components will require a fresh look at the XML standard as it presently exists. While it may be possible to begin work in this direction without changes to the XML standard itself, keeping in sync with all constraints may not be a simple thing to achieve when working with multiple components. Adjusting the XML spec so that it provides a finer-grained approach to processing would simplify this task enormously.
At the same time, the developers of the XML sibling standards should keep in mind the various processing models their standards will require, and try to stick to approaches that can be made to work as components, without the need for complicated large-scale application intervention between contending standards processors.
Both the standards for communications between applications and parsers may need updating to support this level of componentization. SAX needs revision in particular, to provide a richer set of events that accurately present the entire document, including the DTD (and probably comments). It might make sense to create an extended, larger SAX (LAX?) that reflects document events as they occur in a document, not as they move from processing by a parser to an application. A framework for supporting multi-layer SAX processing, like MDSAX, would considerably simplify configuration of such multi-layer parsers. The Document Object Model is already undergoing revision that should make it easier to use DOM trees in a variety of applications, hopefully including component-based applications. At the same time, frameworks for managing this larger number of components will be needed, to help standardize processing and simplify application development.
XML has already provided developers with a low-cost format for exchanging data between applications of different types. Improving that standard by making it easy to create complex application from modularized components would make XML an even greater cost-saver, speeding its adoption in multiple fields. It would also create an arena in which small developers can prosper by creating modules without the overhead needed to build enormous monolithic applications, opening up the development process to a larger number of individuals and organizations.
Comments? Questions? Suggestions? Contact Simon St.Laurent.
Copyright 1999 Simon St.Laurent